
这是一套为本网站(静态博客)量身定制的垂直领域 AI 知识库问答系统。针对传统关键词搜索难以理解语义的痛点,我基于 Dify 平台编排 RAG(检索增强生成)工作流,接入了高性价比的 DeepSeek-V3 模型与 BAAI 向量检索模型。该项目实现了让 AI ‘阅读’并理解我所有的技术文档,通过前端深度适配(CSS Injection),以零成本构建了一个能够精准回答博客相关问题的智能体 (Agent)。 点击右下角的图标
直接体验
静态博客的“数字大脑”(一):基于 Dify + DeepSeek 的 RAG 架构选型与实践
Dify ChatFlow Agent 搭建流程
Dify注册
填入API Key
在右上角进入设置,找到模型供应商,选择对应的模型。
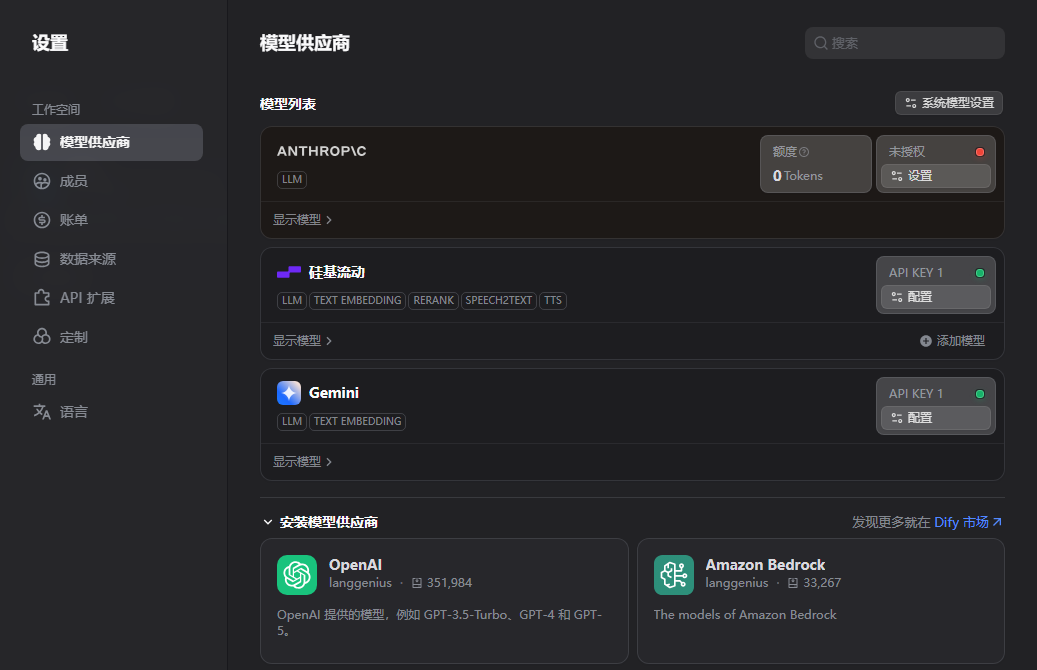
中间一直抽风报错,试了Gemini的API,硅基流动的API,都不行。
后来等一会重新试了一下才好。
创建知识库
链接直达 https://cloud.dify.ai/datasets/create
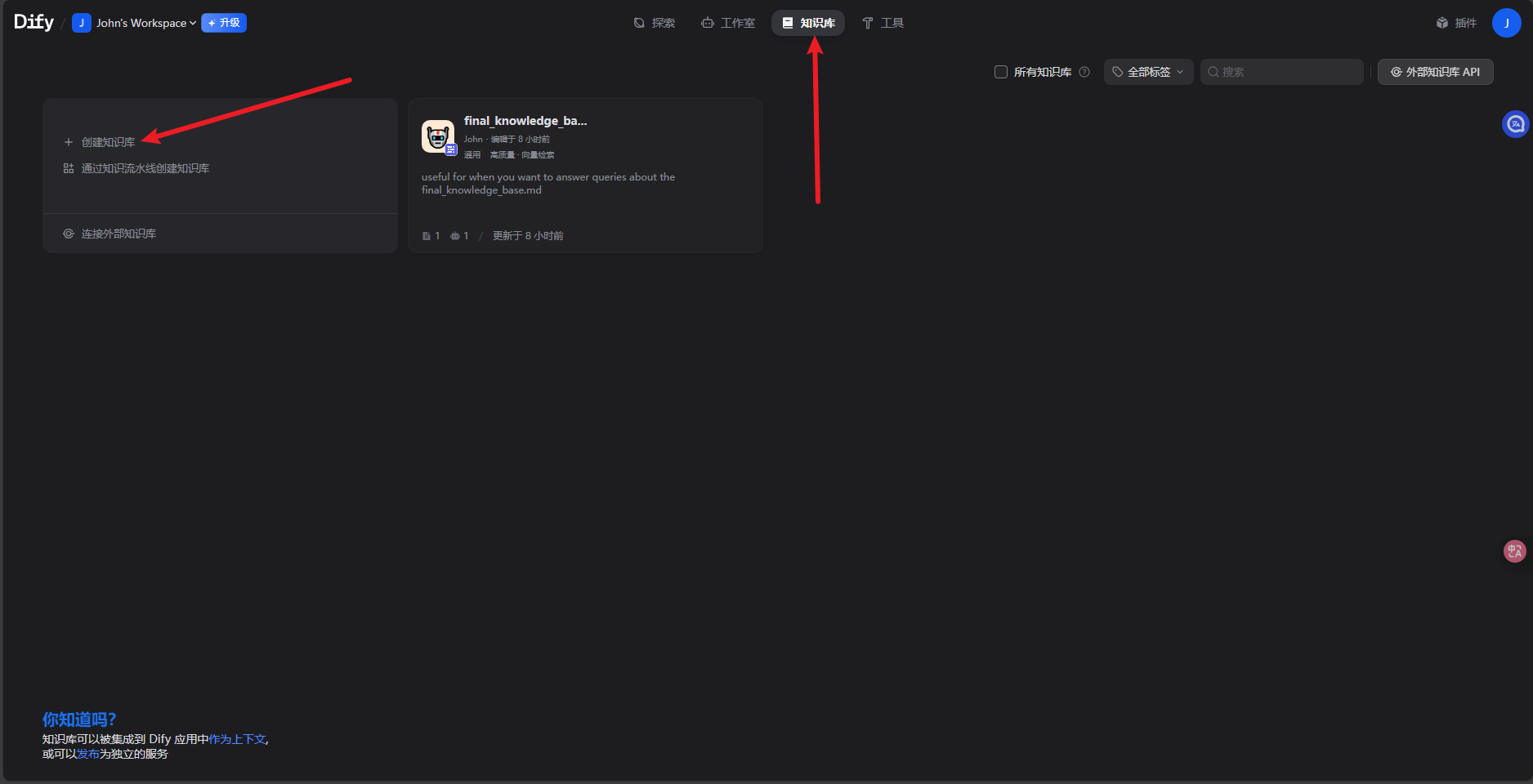
选择数据源
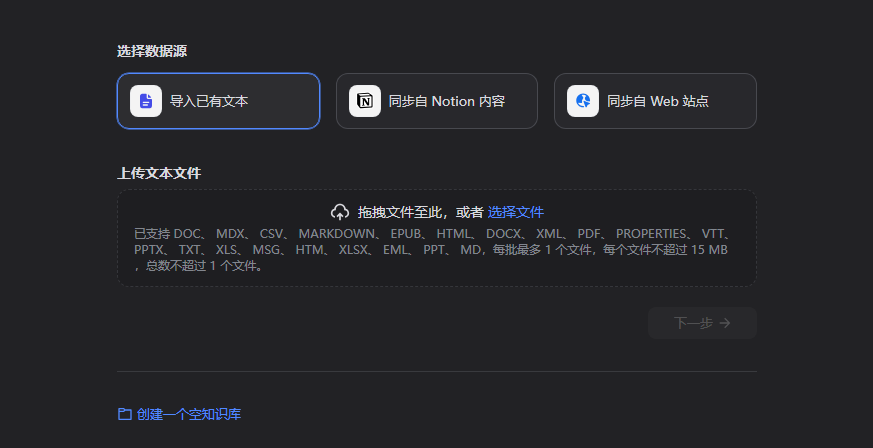
firecrawl.dev 注册,获取API
默认有三种,如果是给网站博客使用的,可以使用最后一种,通过第三方工具爬取你的网站内容,相较于直接导入源文件或者链接笔记仓库,这样相当于直接剔除了你的隐私信息、草稿、多余的文章元数据等等,知识库的数据源和网站访问者看到的是一样的。
该第三方服务需要注册,很简单可以直接使用GitHub登录注册,免费账号有限制,不过不用担心,Dify的限制比它还多。注册后拿到API Key填入Dify进行服务配置。
筛选网站页面
在其中填入网站域名,然后可以设置排除路径和仅包含路径,建议都选上,按照自己的博客结构和情况,进行设置,主要是为了剔除掉一些功能性页面及其所生成的重复页面。
 我的博客都是使用页面包写的,在 Hugo 的页面包(Page Bundle)结构中,
我的博客都是使用页面包写的,在 Hugo 的页面包(Page Bundle)结构中,_index.md(Section 页面)和 index.md(Leaf 页面,即真正的文章)确实有着本质的区别。
文章全都散布在不同位置以及层级的文件夹下面,且文件名都是index,所以处理起来还是比较麻烦。
通过正则清洗掉结构性节点,只保留内容节点
剔除页面:
tags, categories, page, archives, search
我是这样填写保留路径的:
(ai|cs|data|devops|python|util|workflow)/.+
通过收紧正则匹配的方式,让爬虫只抓取“子路径”下的文章,而跳过“根目录”的 Section 页面。
在保留主要的几大板块下面的内容的同时,不会保留根目录以及_index这样的多余页面。
firecrawl.dev抓取的页面是比较多的,但是Dify限制上传文件限制
这就意味着,抓取的这么多页面并不能直接用。
Firecrawl 已经帮我完成了最痛苦的工作——HTML 转 Markdown。它自动去除了 Hugo Stack 主题里的导航栏、侧边栏和脚本。相当于做了数据清洗的工作。这是他的免费账户能做到的了,虽然它限制了页面数(一开始想着能一直用下去,设置了500页面,结果被打断施法,然后改成50个就可以了),虽然限制RPM(一分钟一次),但是它的任务完成了,接下来Dify免费账户承担另一部分工作。
可以在抓取后,自己去 firecrawl.dev 下载那些文件,会打包成一个压缩包。
然后使用python脚本把全部文章合并为一个文档
|
|
最后使用文档上传,作为单一文档进行数据库生成。
自动流程到这里卡住了,另外所有文章合成一个文档,AI没法指出具体是哪个文章讲到哪个内容,这是一个硬伤,但是免费方案没办法,这就是Dify赚钱的地方了,但是59美金一个月的付费不可能交的,考虑后续通过自建工作流绕开或者自己部署Dify实现全程自动化以及精准的回答与文章匹配。
文本分段与清洗
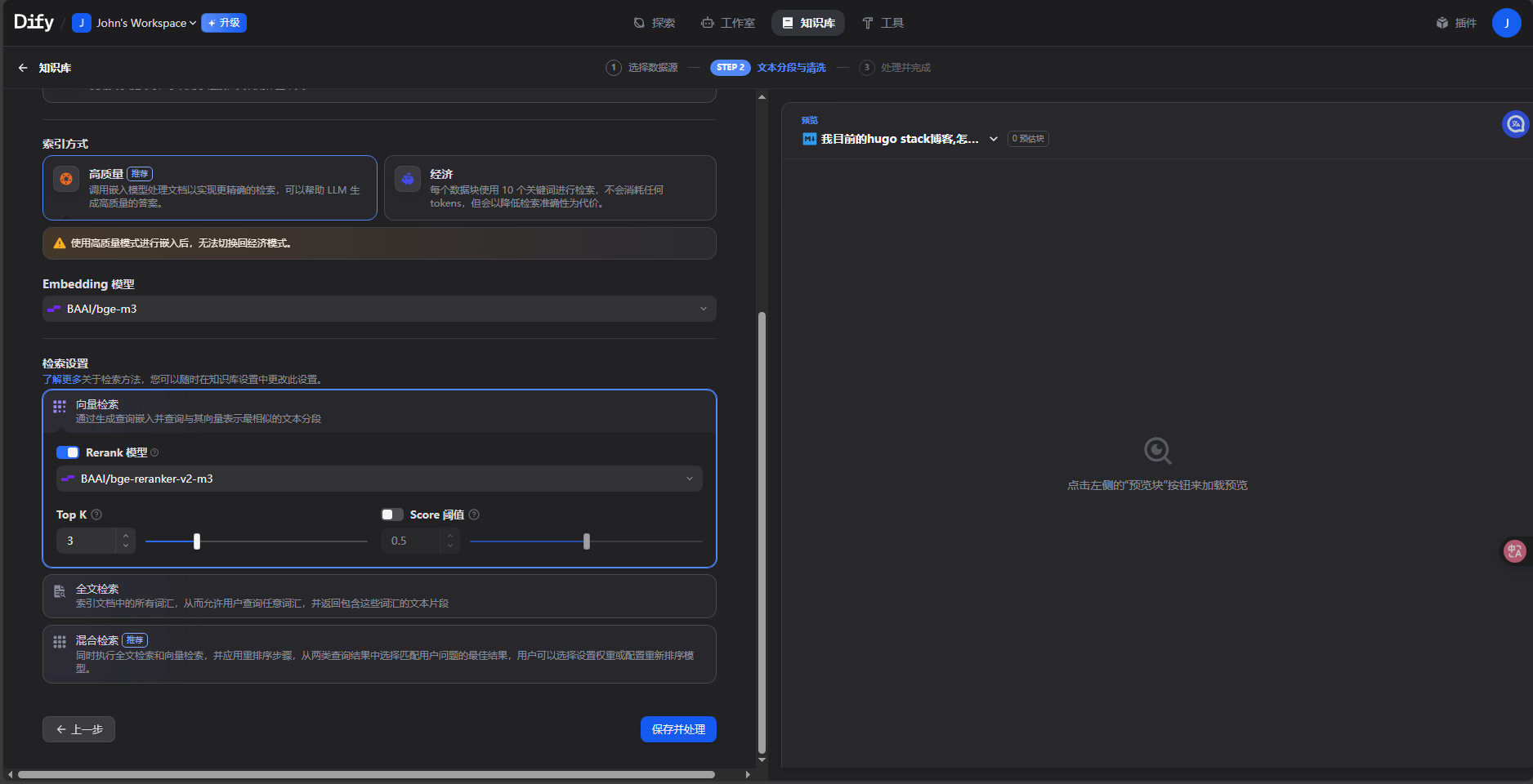
这里其余设置保持默认就行,但是模型选择需要注意,选择和自己的API匹配的,以及确认自己API能够使用的,比如Gemini免费套餐的模型限制,硅基流动的赠额不能使用Pro模型等等,需要在平台上筛选查看可用赠额的模型名称。
这里建议Embedding 模型 选择 BAAI/bge-m3
Rerank 模型 选择 BAAI/bge-reranker-v2-m3
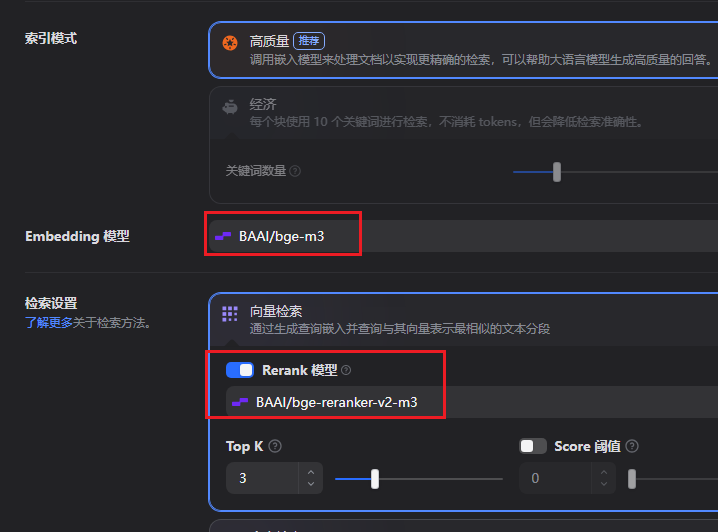
据说是完全够用,然后我发现也是在硅基流动上完全免费的。后面我自己测试了也是觉得非常好用。
API 报错,知识库创建失败,硅基流动改政策
用了谷歌和硅基流动的API都出错了。
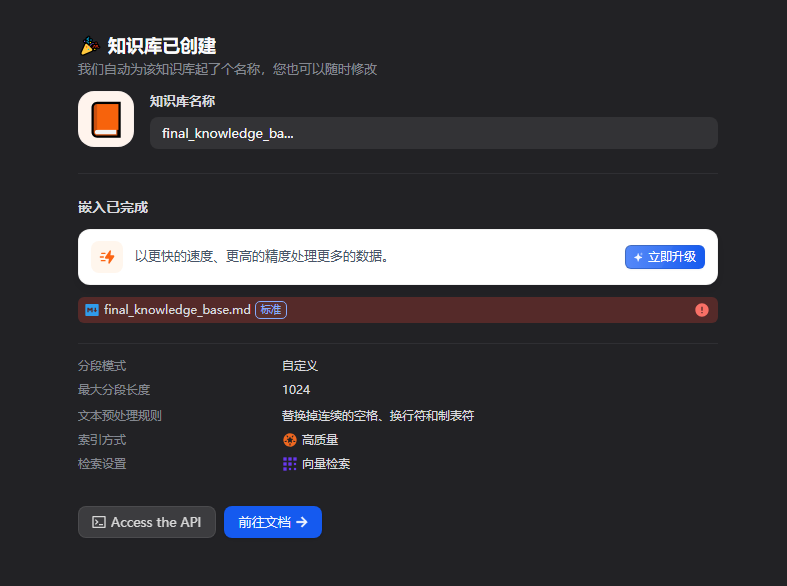
后来发现是Gemini的免费模式限制频率,然后使用硅基流动的,结果也报错,后来排查一圈,又登上硅基流动官网,才发现最近改政策了,未认证的用户也限制RPM了。

然后就认证了一下,正常使用了。接下来就可以在应用中添加知识库了。
创建应用
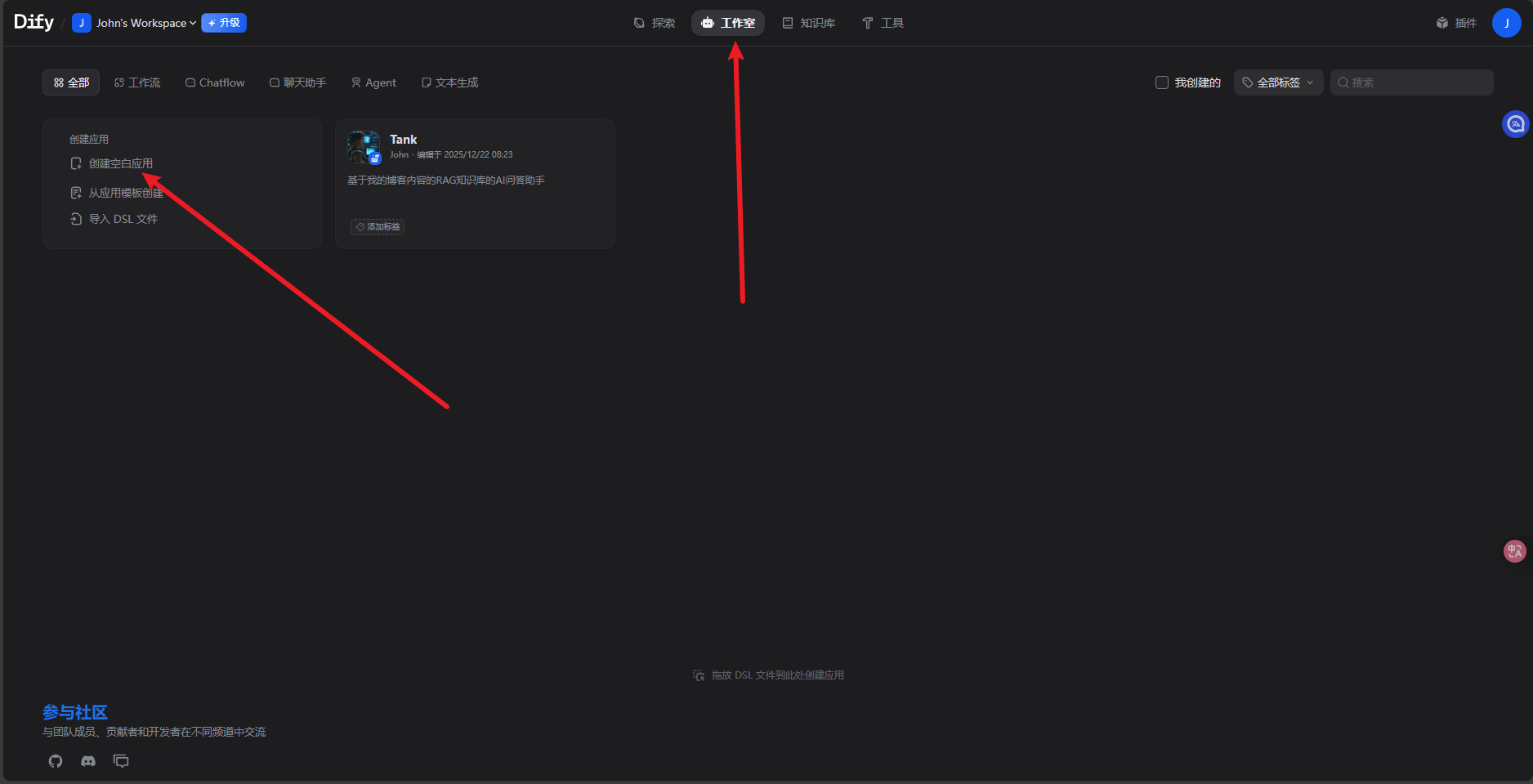
选择ChatFlow,进去随便起个名,名字和头像后面都可以随便换。
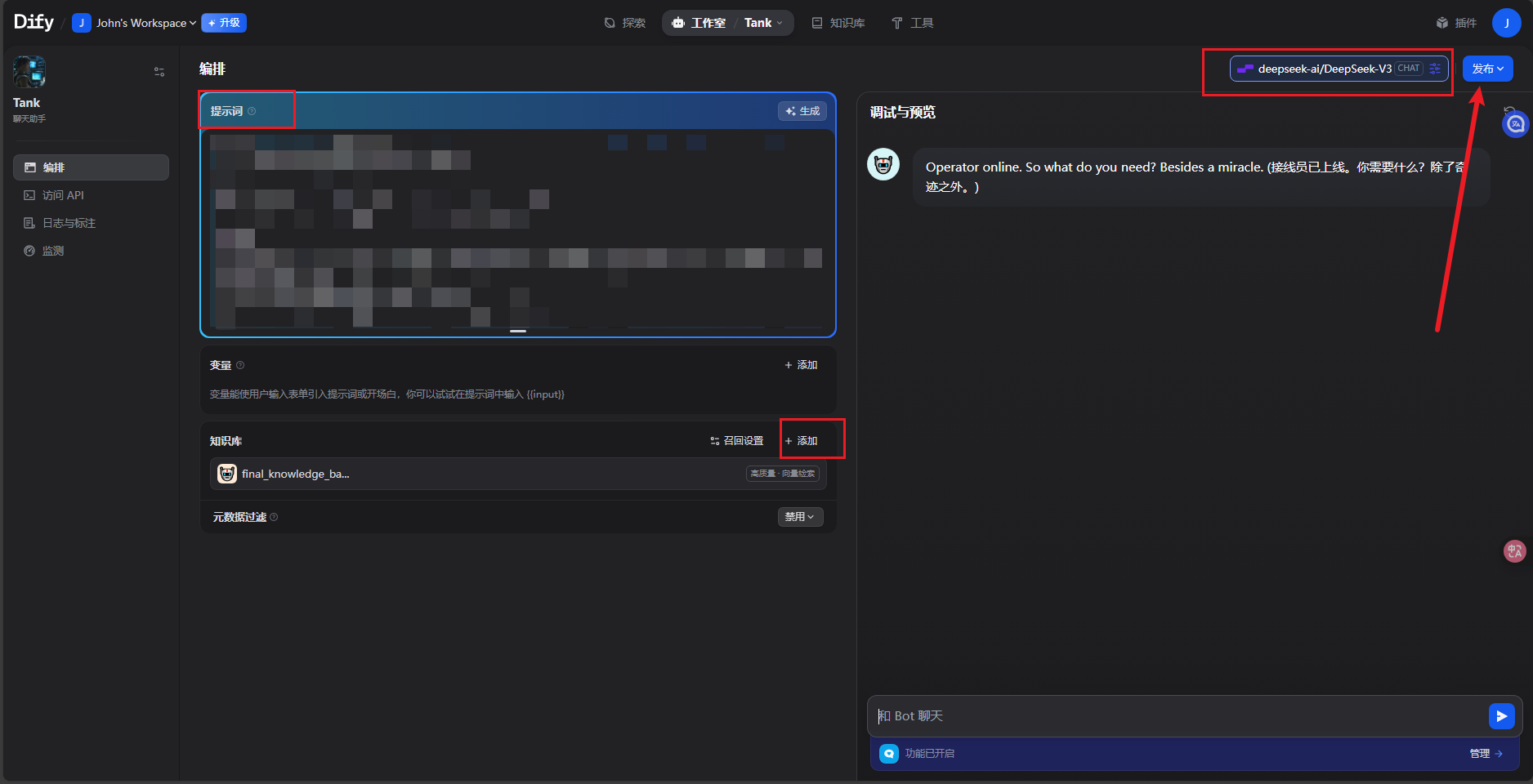
进去之后主要有三块需要配置
1.提示词,这个建议找个ai帮你写,或者他这里直接有帮你ai生成提示词的。
2.知识库,选择添加我们之前创建好的RAG知识库。
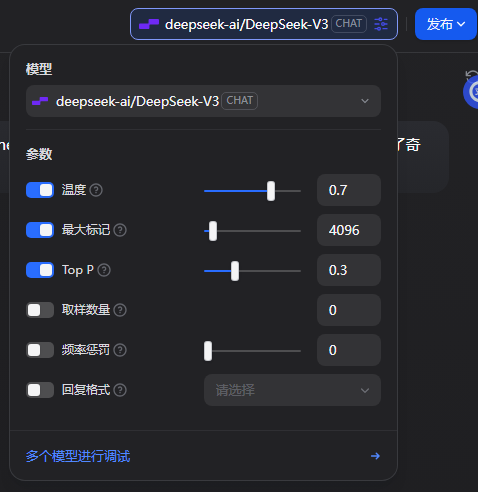
3.模型选择及配置,在右上角选择模型。建议直接选DeepSeekV3,文字问答很强,且硅基流动赠额可用。 下面的配置就挺好,温度越大越人性化;最大标记默认值太大了,用不到,改成4096就足够;Top P 0.3保证人性化的同时不会无凭无据乱说话。
全部设置好之后在下面测试聊天,没问题的话点击右上角发布,然后点发布旁边的下拉框选择嵌入网站。
获取嵌入网站的代码
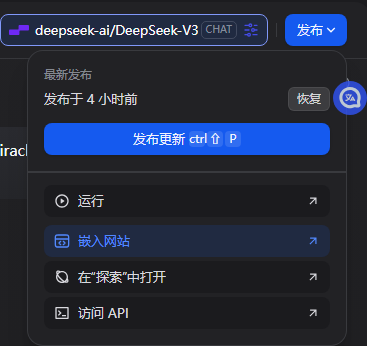
有三种形式
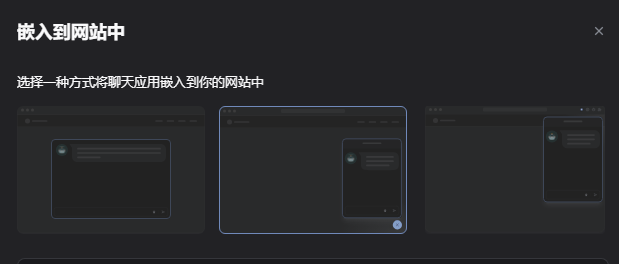
第一种适合把聊天当作主要功能之一的,第二种聊天框没那么大,第三种适合给自己使用,需要搭配浏览器插件。
我使用第二种,并且后面可以通过代码调整,可以做到随时切换到近似第一种的样式。
选好之后在下面点击复制代码。
嵌入 Hugo Stack
hugo stack预留了空白的 custom.html 可以直接填进去,不过我使用主题子模块形式来确保原文件的纯净,不受今后主题更新的干扰,所以我在项目根目录创建相同的目录及其文件来进行覆盖。
新建文件在
项目根目录/layouts/partials/footer/custom.html
将Dify的网站嵌入代码粘贴保存,重启hugo,在网页上刷新查看。
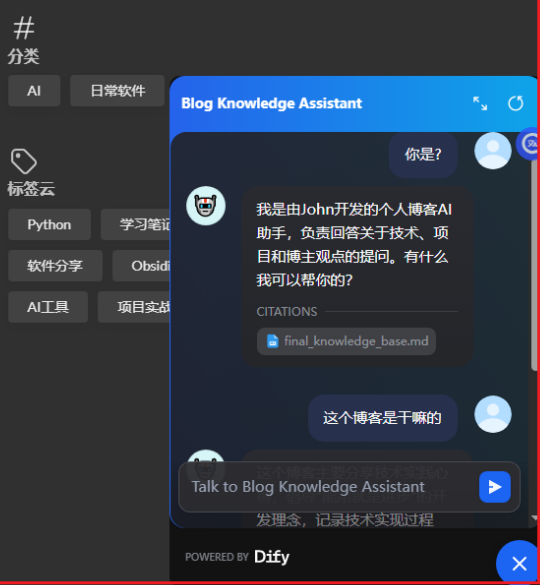
成功加载,并且可以进行问答操作。
架构选型篇 —— 打造静态博客的“数字大脑”
探索 RAG (检索增强生成) 架构在静态站点中的应用实践。通过接入 AI 助手,实现从传统关键词检索到智能语义交互的跨越,为静态内容注入动态的交互深度。
觉醒:给静态博客装上一个“数字大脑”。
人人都幻想过拥有一个极其懂自己的助手。
提到这个概念,绝大多数人脑海中跳出的第一个名字一定是贾维斯(Jarvis)。作为一个曾经刷完了 MCU 及其全系衍生剧的资深漫威粉,我也曾疯狂迷恋那种“全知全能”的管家式交互。
但当我真正开始折腾 AI、开始深入研究如何给我的 Hugo 静态博客接入大模型时,我发现那种坐在屏幕前,看着光标跳动,与人工智能这种硅基生命进行对话、交换信息的过程,并没有那么多的“管家味”。
这种跨越物理世界与数字矩阵的通讯,其实更像是《黑客帝国》(The Matrix)里的场景。那个坐在层层叠叠的显示器前,看着绿色代码雨,在关键时刻为你指引出口、上传技能包的人。
所以,这个 AI 助手在我的博客里,其身份不再是一个贴心的管家,而是一名“接线员”(Operator)。
1. 技术背景:静态博客的“交互”困局
目前的个人博客是基于 Hugo (Stack 主题) 构建的静态站点。虽然静态博客在加载速度和安全性上有天然优势,但在知识检索方面存在明显的局限:
- 传统检索的局限性:内置搜索通常基于关键词匹配,无法理解用户的真实意图。如果访客想要寻找关于某个技术栈的综合观点,传统搜索只能给出碎片化的文章列表。
- 内容的静态性:静态站点缺乏后端逻辑,无法根据读者的提问实时提炼内容。
为了打破这种僵局,我决定引入 RAG (Retrieval-Augmented Generation) 架构,通过大语言模型(LLM)来检索并理解博客内容,从而为访客提供精准的问答服务。
2. 技术选型:在一众平行方案中寻找“平衡点”
在静态博客中引入 AI 聊天工具,核心难点在于静态页面没有后端,不能直接暴露 API Key。经过横向测评,我对比了目前主流的三种流派:
- 方案 A:成品 SaaS 嵌入流 (如 Coze/Chatbase)
- 特点:零代码集成,自带 RAG 知识库。
- 权衡:虽然方便,但定制化程度受限,且往往带有明显的平台水印或受到额度限制。对于追求自主权的开发者来说,缺乏调优的空间。
- 方案 B:Serverless 转发流 (手写代理逻辑)
- 特点:灵活性最高,通过 Vercel 或 Cloudflare Workers 转发请求以隐藏 API Key。
- 权衡:虽然能展示代码功底,但对于个人博客而言,从零维护一套问答 UI 和后端转发逻辑的成本略高,容易偏离“专注内容”的本心。
- 方案 C:低代码平台 (Dify) —— 最终选择
- 理由:Dify 作为一个开源的 LLM 应用开发平台,平衡了“开箱即用”与“深度定制”。它支持 Markdown 知识库自动分段(Chunking),提供现成的 Web SDK 嵌入方案,且允许博主完全控制底层模型和 RAG 参数。
3. 模型决策:DeepSeek 与成本控制
为了实现低成本甚至接近“零成本”的长久运行,我选择了 DeepSeek-V3 模型,并经由 SiliconFlow (硅基流动) 平台进行托管。
- 性价比优势:DeepSeek 的 API 价格极具竞争力,配合第三方平台的赠额,可以实现极低成本的 API 调用。
- 模型中立性:Dify 支持通过 OpenAI 兼容模式接入各种模型,这让我可以根据模型表现随时灵活切换,而无需改动前端代码。
4. 落地实施:Hugo 架构的“零侵入”集成
在集成过程中,为了不破坏 Hugo Stack 主题的子模块(Submodule)源码,我采用了 Partial 模板覆盖机制:
- 发布应用:在 Dify 平台完成 Agent 编排后,发布为“WebApp”,并获取一段嵌入脚本。
- 创建钩子:利用 Stack 主题预留的自定义入口,在博客根目录创建
layouts/partials/footer/custom.html。 - 注入代码:将 Dify 提供的脚本粘贴至此。根据 Hugo 的查找优先级(Lookup Order),根目录的这个文件会优先被渲染,从而在不改动主题源码的前提下,为全站加载 AI 插件。
5. 第一阶段复盘
目前,博客的“数字大脑”已经构建完成,整体架构在逻辑上已经跑通。通过 Dify Cloud,我实现了一个不需要额外租用服务器(VPS)、不需要维护后端数据库的高效 AI 问答助手。
然而,这仅仅是“连接”的开始。在实际部署后,我遇到了更具挑战性的问题:由于静态站点的页面包结构,如何高效、自动地清洗并喂养知识库数据?以及如何通过 CSS 深度魔改,解决嵌入窗口与主题样式的视觉冲突?
这些细节,我将在下一篇关于数据工程与前端调优的内容中详细展开。
💡 技术笔记: 由于 Dify WebApp 的性质,我们在集成时必须注意 HTTPS 协议的一致性,并建议在 Dify 后台配置频率限制,以防止 API 余额被恶意消耗。
正如在数字化世界中,每个系统都需要一位“接线员”(Operator)来处理信息流。通过这一套 RAG 架构,我成功为自己的静态领地建立了一个初步的通信接口。