
Web-Retrace(一) 桌面后端与浏览器插件开发记 -【Google Antigravity】尝鲜体验
项目地址
目前还在完善中
起因
今天搜索浏览器历史记录感觉不太爽,发现经常是想起来以前浏览过一个什么页面,但是搜不到,然后突发奇想能不能做一个浏览器历史记录的rag程序,直接抓取浏览过的内容,我都不用再找到那个页面打开浏览了,直接问就行,看过的网页就等于记住了。
然后想找个免费的agent试试,vscode之前薅的智谱感觉不好用,插件的理解力还是不足。
在linux.do看到有人讨论Antigravity,说什么Cursor都不香了。 吓得立马丢掉Trae,(主要是不给我开放Solo模式,Trae的builder模式不太行。
Gemini3.0pro说他不认识,然后被我打脸了
1. 背景与需求 (Background)
-
原始痛点: 浏览器自带的历史记录(
Ctrl+H)只是简单的 URL 列表,无法检索页面内容。很多看过的技术文档和博客,过段时间只记得“大概看过”,却死活搜不到。 -
技术选型思路:
-
Local-First(隐私): 浏览记录涉及隐私,必须本地存储。
-
RAG(架构): 需要语义检索,而不仅仅是关键词匹配。
-
Stack: Python (FastAPI) 做后端 + ChromaDB 做向量库 + Chrome Extension 做入口 + DeepSeek V3 做总结。
-
-
开发模式: 尝试全流程使用 AI IDE(Google Antigravity)辅助开发。
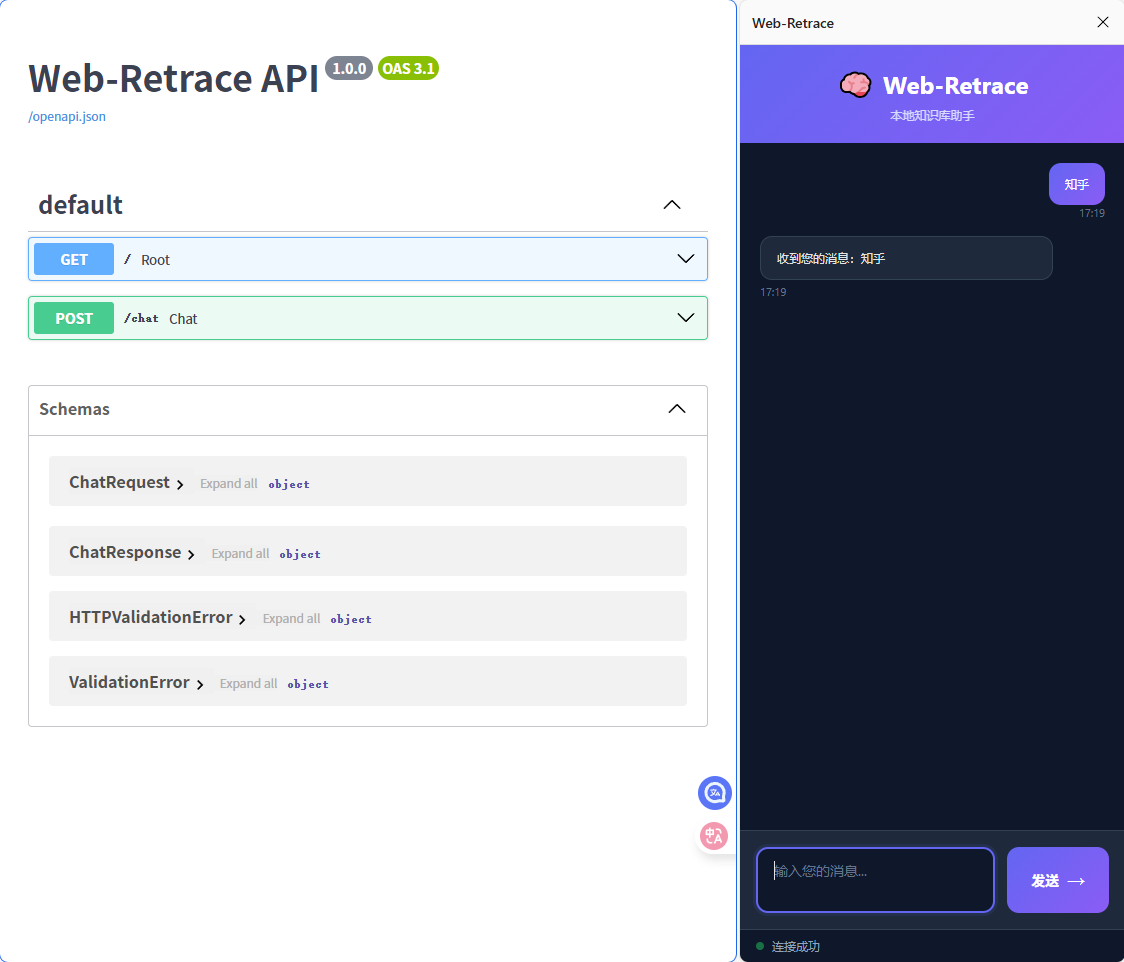
2. Phase 1: 最小化验证 (MVP) - 跑通通信链路
-
初始目标: 实现一个最简单的“Hello World”闭环:Chrome 插件发送请求 -> Python 后端接收 -> 返回响应。
-
遇到的坑:
-
IDE 交互逻辑: Antigravity在使用 Agent 模式时,手动
Ctrl+C杀死了服务,但 Agent 状态机认为任务还在运行,导致无法下达新指令。 -
解决: 理解了 Agent 的生命周期,通过新对话继续下指令。
-
-
阶段产出: 确立了
extension/和backend/的目录结构,验证了 FastAPI 与 Manifest V3 的跨域通信(CORS)。
3. Phase 2: 数据存储 (Storage) - 向量库的接入
-
功能实现: 在插件侧增加 “Memorize” 按钮,通过
scriptingAPI 获取document.body.innerText,存入本地 ChromaDB。 -
遇到的技术坑:
- 权限问题: 插件报错
Cannot access contents。原因是 Manifest V3 对主机权限管控严格。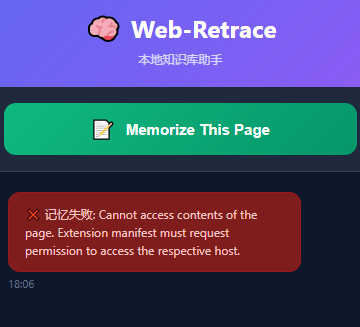
- 解决: 手动在
manifest.json中添加host_permissions: ["<all_urls>"]并重载插件。
- 权限问题: 插件报错
|
|
-
检索效果差异: 初步测试发现,单纯的 Vector Search(向量检索)在面对长网页时效果很差。搜索关键词,返回了大量包含该词但无关的页面。
-
技术反思: 意识到 Raw Text(原始网页全文)直接入库会导致语义稀释。单纯的数据库查询(Retrieve)无法满足需求,必须引入生成层(Generate)。
4. Phase 3: 智能增强 (Intelligence) - 引入 LLM 与切片策略
-
架构调整: 引入
LangChain进行文本处理,接入DeepSeek-V3API 进行问答。 -
遇到的技术坑(重点):
- 依赖冲突(Dependency Hell): Python 3.13 与旧版
langchain==0.1.0不兼容,导致numpy编译失败。shell from langchain_text_splitters import RecursiveCharacterTextSplitter ModuleNotFoundError: No module named 'langchain_text_splitters' - 解决: 解除版本锁定,去掉 requirements.txt 中指定的版本号,使用 pip 安装最新版依赖。
1 2 3 4 5 6 7 8 9fastapi uvicorn[standard] python-multipart chromadb langchain langchain-community langchain-text-splitters openai python-dotenv-
Recall(召回率)过低: 即使接入了 LLM,模型依然回答“我不知道”。
-
Debug 过程: 发现是默认参数设置不合理。
chunk_size=500导致上下文支离破碎,top_k=5导致相关片段被网页噪声(广告/导航)挤出候选集。
- 依赖冲突(Dependency Hell): Python 3.13 与旧版
-
参数调优:
-
Chunk Size: 调整为 1000 字符(重叠 200)。 -
Top K: 调整为 15。
-
|
|
- 最终效果: DeepSeek 能够从 15 个长片段中精准提取出被折叠或角落里的信息,实现了真正可用的 RAG 问答。
5. 总结与下一步 (Summary)
-
当前状态: 完成了一个可用的本地 RAG 原型,成本极低(依赖 DeepSeek 免费 Token 和本地 ChromaDB)。
-
AI 辅助编程体验: AI 在生成样板代码(Boilerplate)上效率极高,但在环境配置(版本兼容性)和业务逻辑调优(参数设置)上,依然需要人的经验介入。
-
Todo: 计划实现基于“停留时间”的自动价值评估算法,解决手动点击繁琐的问题。