
给9年前买的办公本装上Ollama,跑Qwen3
近期内存条和硬盘价格疯涨,本想把老笔记本上的内存条卖掉,之前160一根的现在都涨价到540了,一根16g内存条比之前回收平台预估的电脑整机回收价格还高了。
挂到小黄鱼卖三百块,结果全是贩子在收,突然不想卖了。
毕竟有24G内存,能跑一些吃内存的服务,还有个当年入门级英伟达显卡,索性让这台机子发挥一下余热,感受AI时代的光辉,也顺便让当年这个鸡肋的2G显存的940MX显卡一雪前耻。
准备给它先装个Qwen3-0.6B试水。

准备工作
这台老电脑的部分按键已经不灵敏了,决定使用远程操作。
先使用网线直连两台电脑,分别在两台电脑上给该LAN口手动指定同一网段IP,然后使用远程桌面连上这台旧电脑。
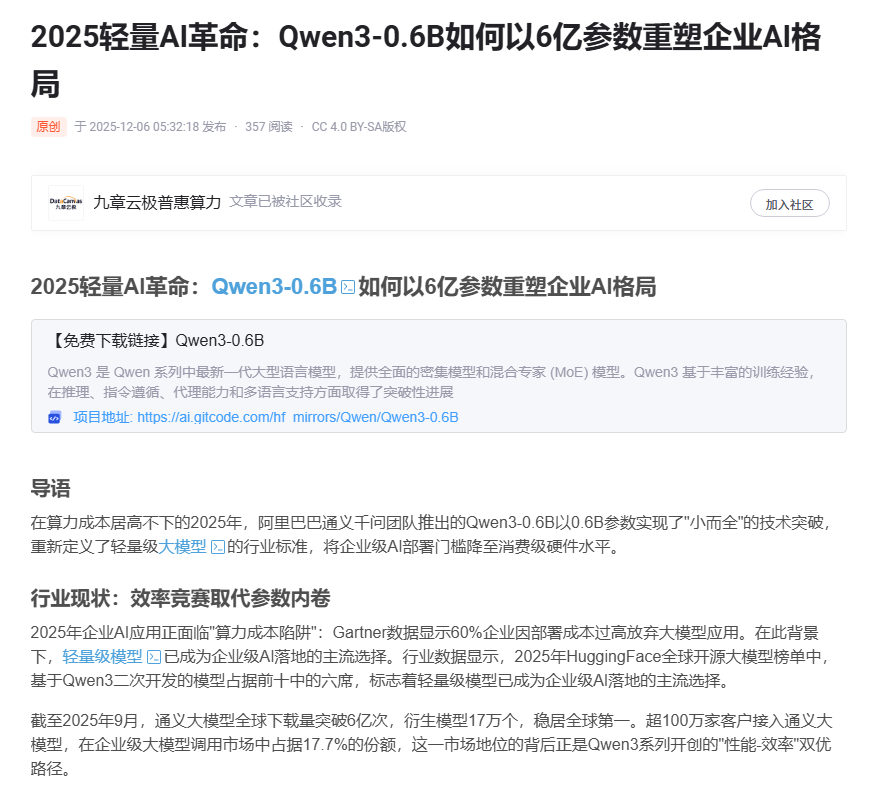
安装最新版Docker,结果提示WSL版本需要升级,看来这台电脑还是WSL1。
打开powershell(需要使用管理员权限运行,否则会安装失败),运行wsl --update,结果进度条不走。

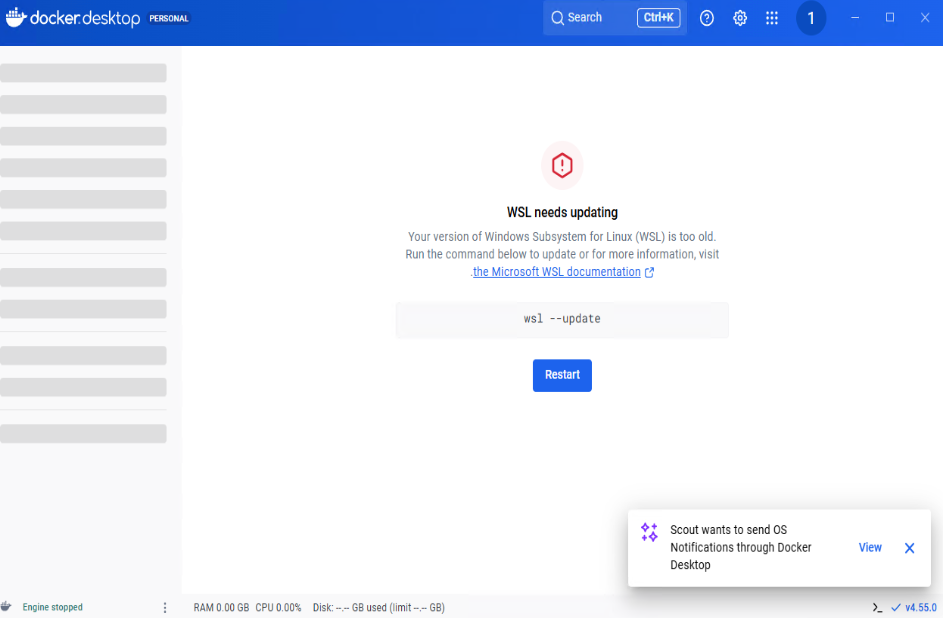
运行wsl --update --web-download,这是借用微软商店的源,结果下载很慢,换US节点后速度正常。
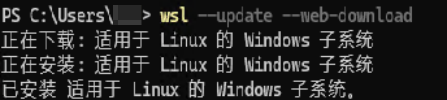
运行wsl -l -v检查版本,发现Ubuntu还运行在wsl1。

运行wsl --set-version Ubuntu-24.04 2,转换到wsl2.
避免今后的实例运行在wsl1,设置wsl2为默认值。wsl --set-default-version 2

安装Ollama
准备工作做完,可以在当前电脑直接通过ssh连接它进行操作了。 直连对面wsl
ssh -t 用户名@192.168.x.x “wsl”
启动 Ollama 服务容器
复制并运行这条命令。它会启动 Ollama 的后台服务:
|
|
发现报错
|
|
镜像已经下载成功且校验通过了,最后显示11434 端口已经被别人占用了,或者 Docker 的网络桥接出了一点小故障(status 500)。
Status: 500 报错大概率是 Docker Desktop 自身网络组件抽风,或者是 Windows 的 WinNAT 服务 把端口“卡”住了。
检查端口是否被占用
打开 PowerShell。输入这行命令查端口:
|
|
结果什么都没显示,端口其实是空的,根本没被占用。
真相是 Docker Desktop 的网络驱动(WinNAT)卡死了,导致它误以为端口不可用。
重启winnat解决网络问题
这是解决 unexpected status: 500 的万能药。
退出 Docker Desktop(右键右下角鲸鱼 -> Quit)。
以管理员身份 打开 PowerShell。
依次执行下面两行命令(重启 Windows 网络地址转换服务):
|
|
重新启动 Docker Desktop
清理同名容器
清理之前创建失败的Ollama容器
|
|
再次执行启动命令
|
|
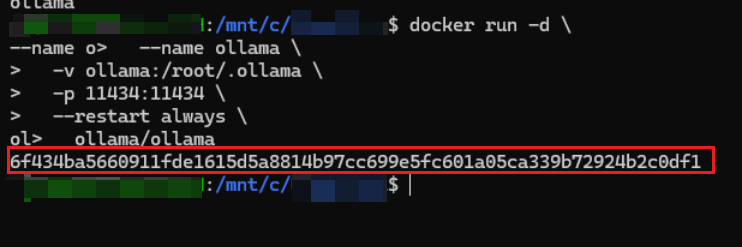
成功部署Ollama
看到这一长串容器id就说明成功了。
部署Qwen
启动 Qwen3 0.6b
b(billion)是十亿,这个参数只有6亿。
在wsl里运行
|
|
成功启动
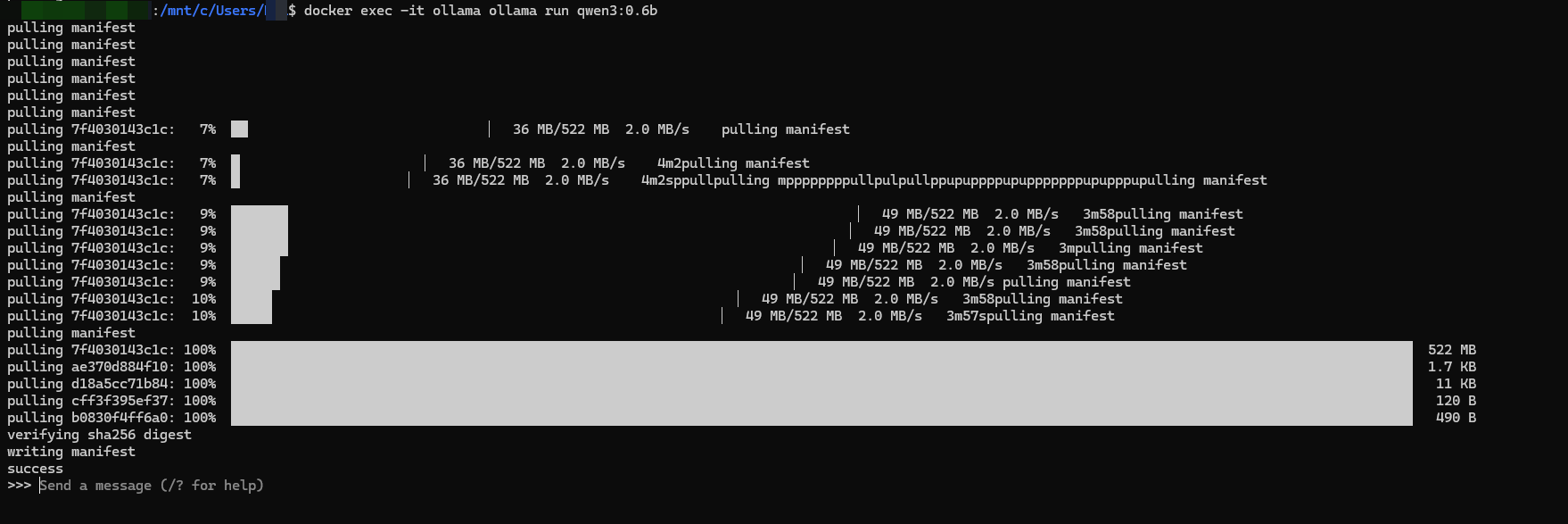
可以直接在这里对话了。
测试性能
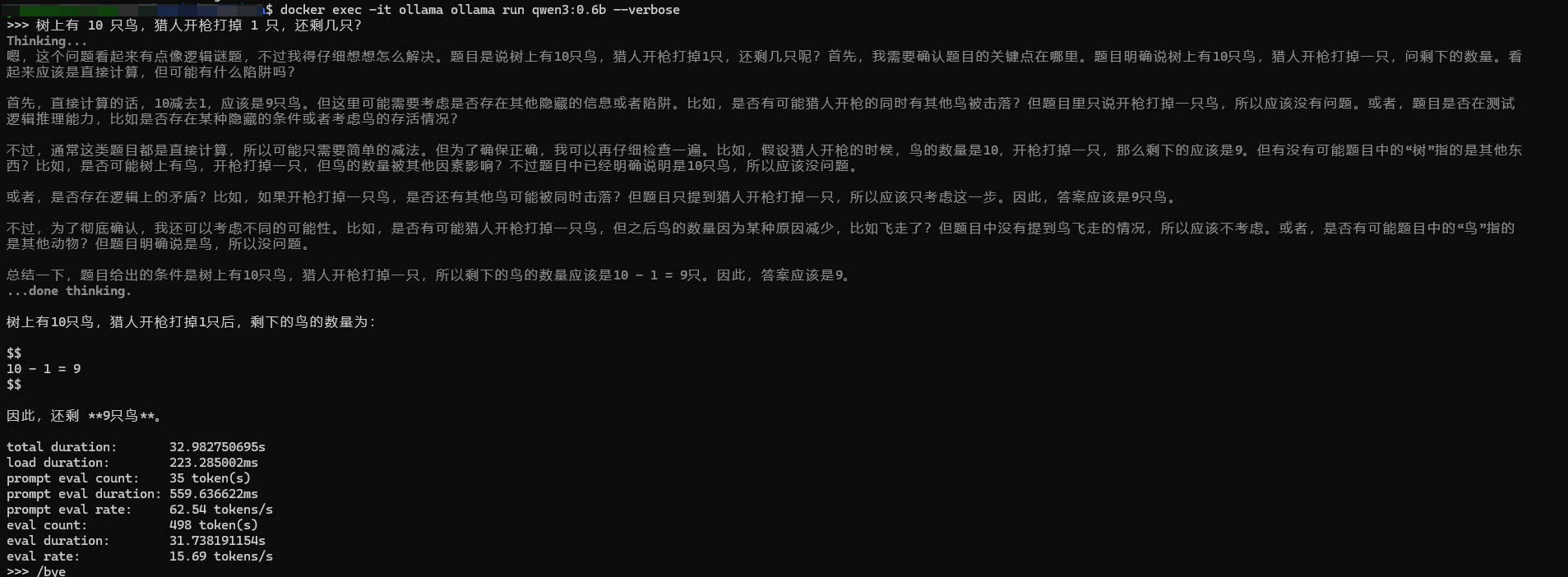
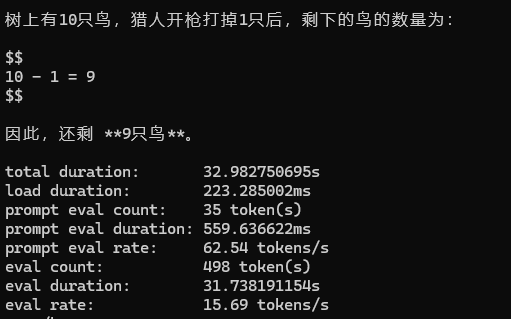
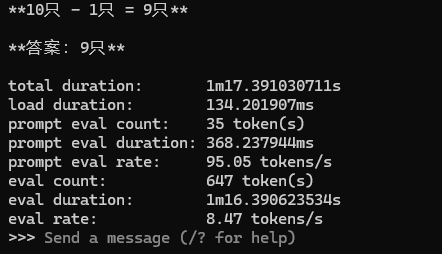
加上--verbose运行,问了个脑筋急转弯,果然被绕进去了,不过这个eval rate15个tokens/s还是可以的,这台9年前的老电脑跑这个最小qwen3-0.6b模型还算流畅。
尝试Qwen3 14b
看着还有14g的空闲内存,感觉可以试试换个大的,看看这个机器的性能与体验的边界在哪。
14b文件大小接近10g。
测试14b性能
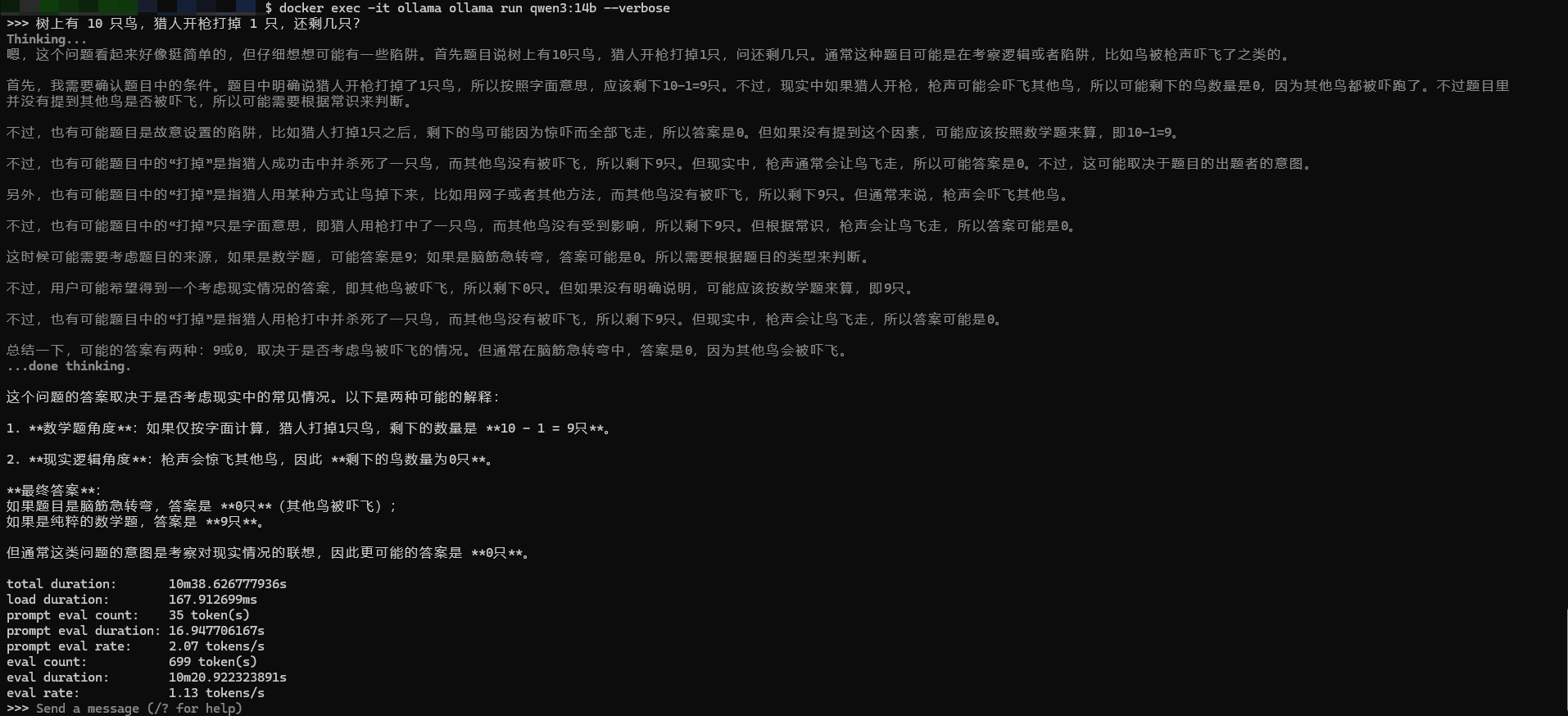
能跑起来,14b显然聪明许多,都能够分情况讨论了,并且回答的没毛病,但是就是太慢了。
尝试将qwen-1.7b放进显存里跑
本机独显是10年前的Nvidia 940MX GDDR5 2G,在当年就属于垃圾的入门显卡,玩网游都卡,通常都做法是屏蔽独显以提升性能;)
但是它支持CUDA啊,我想到可以把qwen3-1.7b刚好放进去,试一下看看效果如何,在我多放求证后,发现这款机子恰好不是当年那批GDDR3的,所以带宽还是要比这个双通道内存快点的。
先用内存跑一下

速度和0.6b相比是减半还不止,但是依旧一样笨。0.6b的含金量又上升了hhh
总结
实践证明,这台9年前的老机器,双核四线程,低压cpu,24G内存,也能跑当下最新的LLM,只要内存够。
qwen3-0.6b在这台机器运行可以说是很流畅了,但是14b就慢的很,毕竟参数差了23倍。
后续尝试使用这台机器做一些非实时性的任务。
Qwen3-0.6B 的官方定位
阿里官方明确将 Qwen3 系列称为 “新一代大型语言模型“Qwen,Qwen3-0.6B 作为该系列的最小成员:
- 参数规模:0.6B(6 亿),低于传统大模型标准
- 但官方仍将其归类为 “轻量级大模型“或”微型大语言模型”
技术演进视角
- 随着 AI 技术发展,“大模型” 概念已从单纯的参数规模扩展到 “预训练 + 微调” 的技术范式
- Qwen3-0.6B 虽参数小,但采用与大模型相同的训练方法和技术路线
实用价值定位
- 官方定位为 “毛细血管级 AI",能渗透到传统大模型无法到达的场景
- 解决了 “大模型能力与小设备部署” 的矛盾,使 AI 能力普及到消费级设备